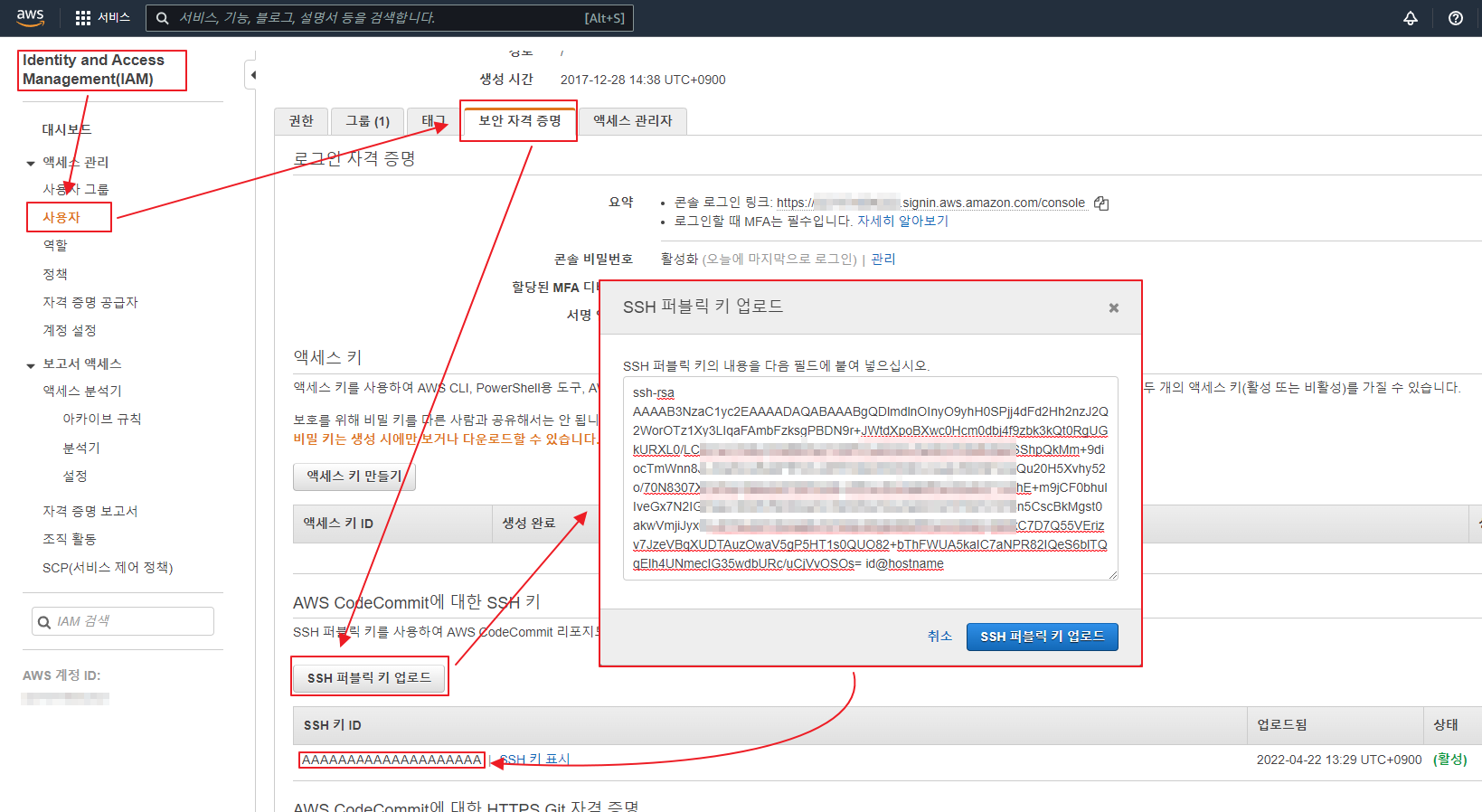
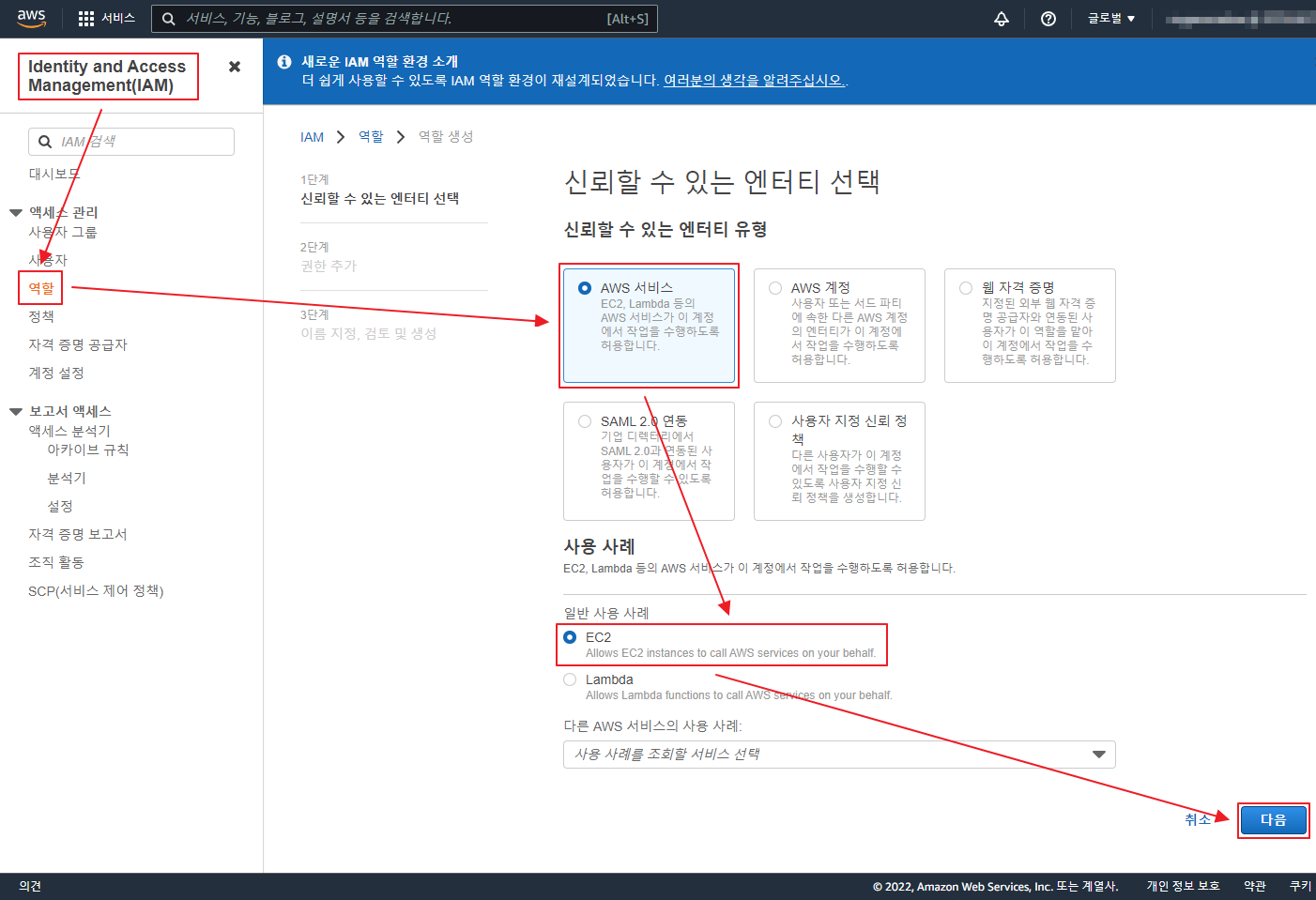
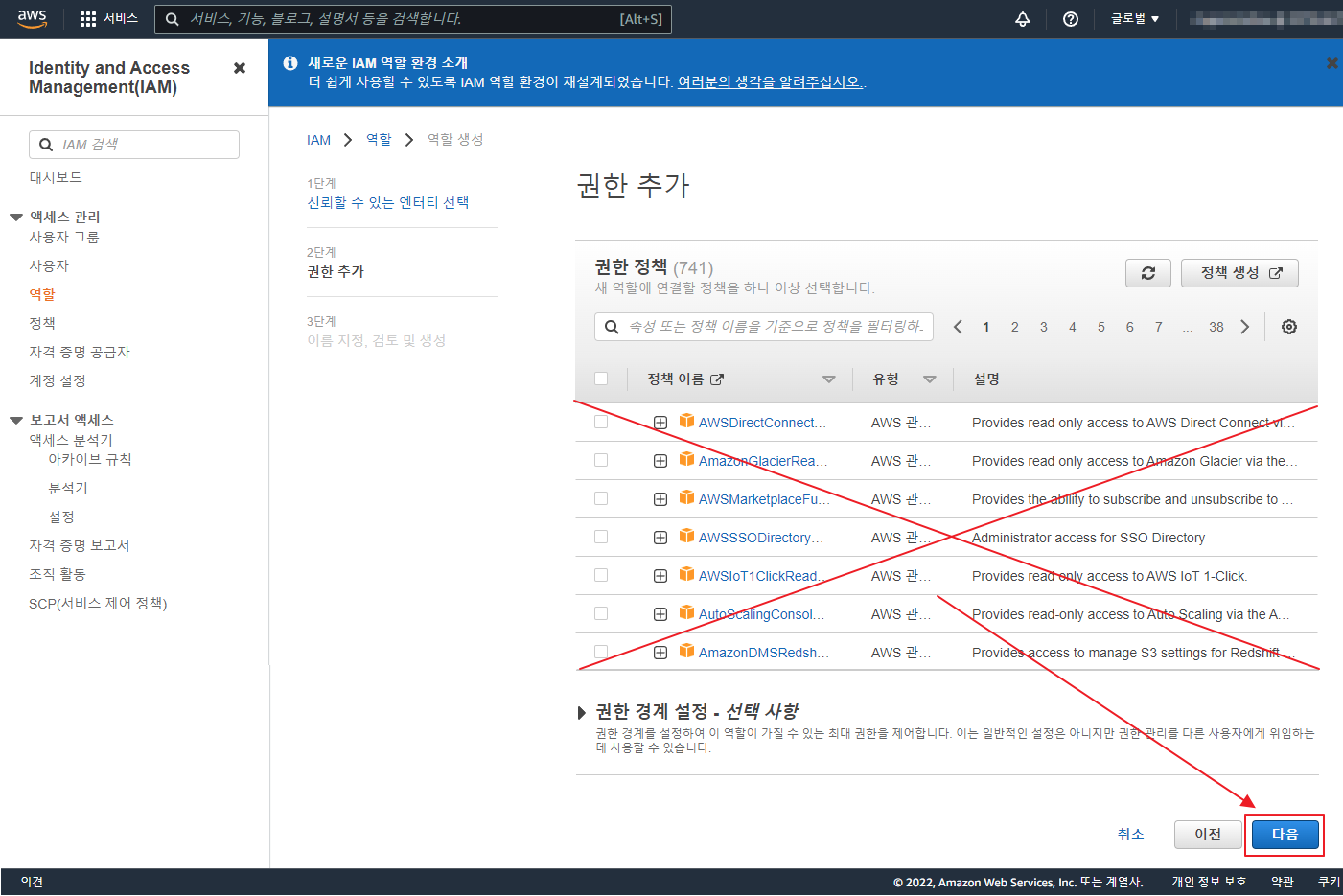
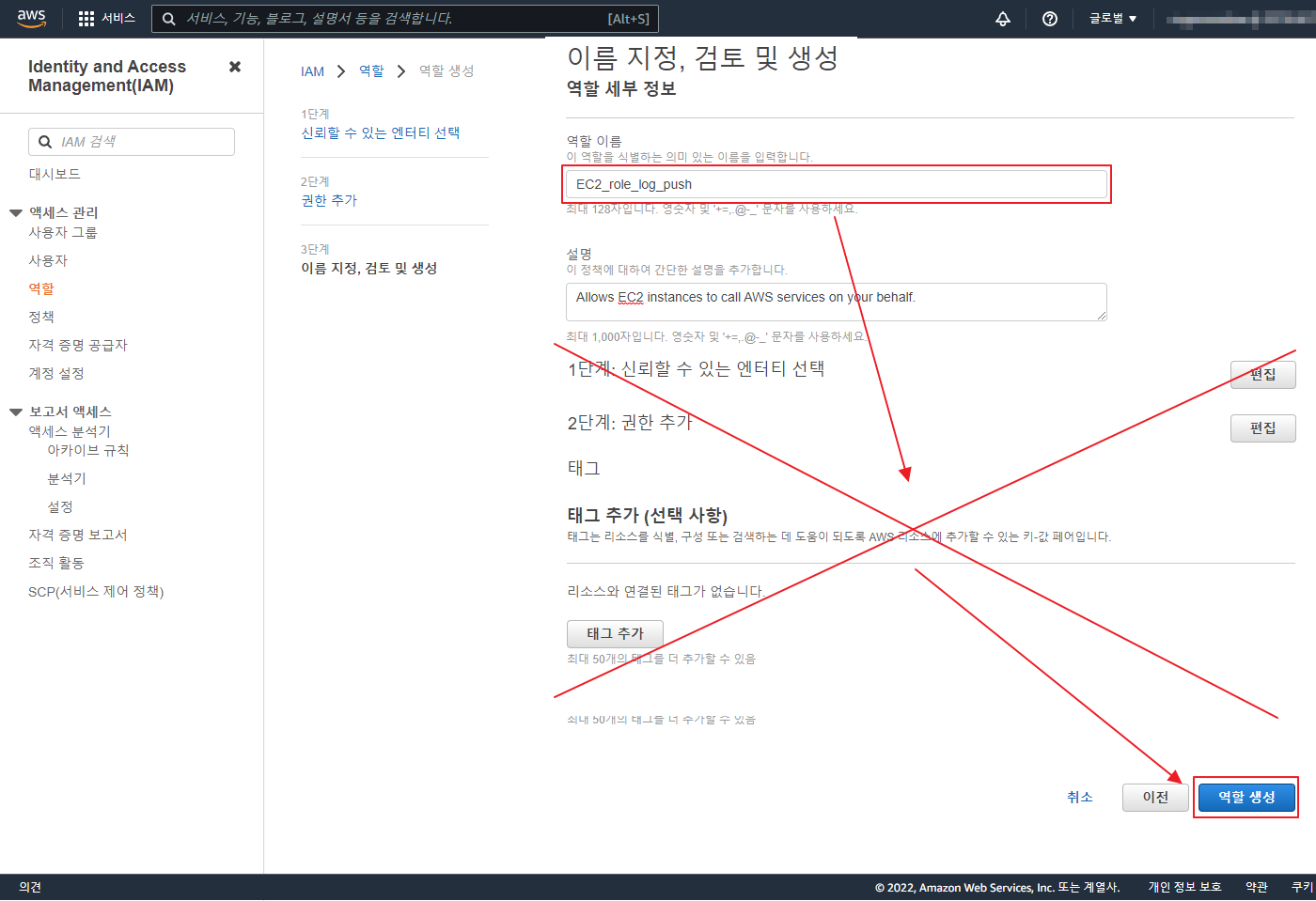
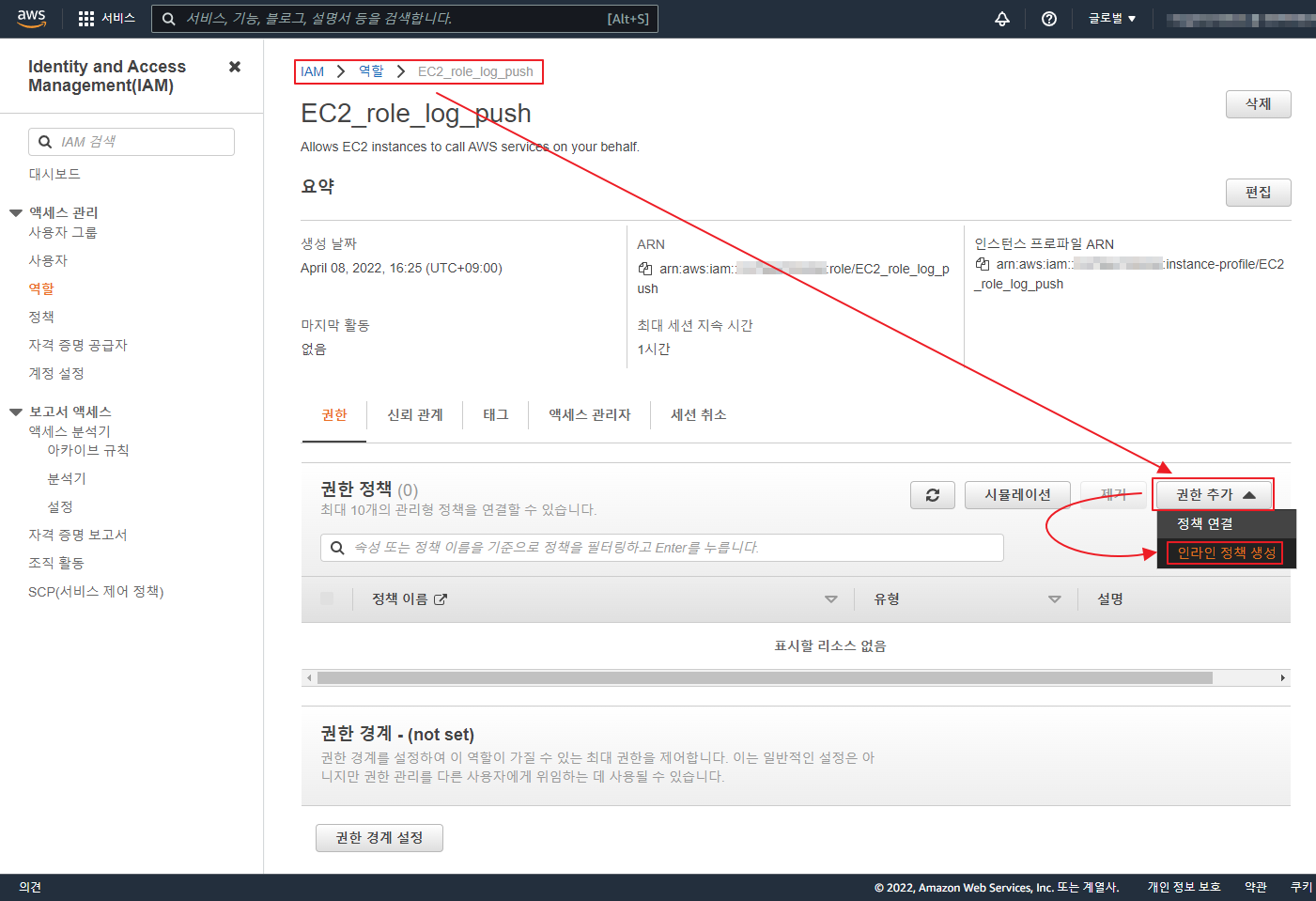
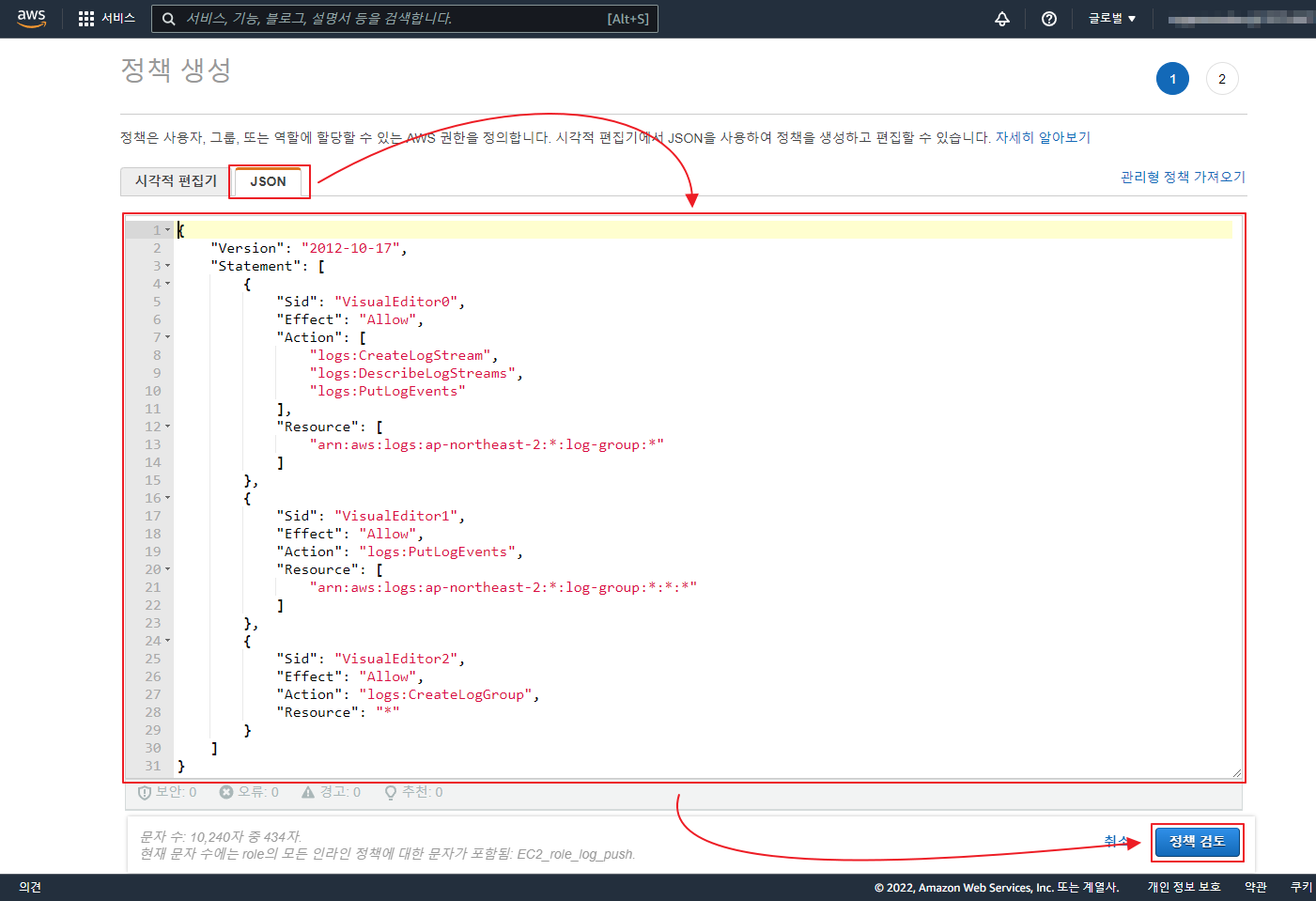
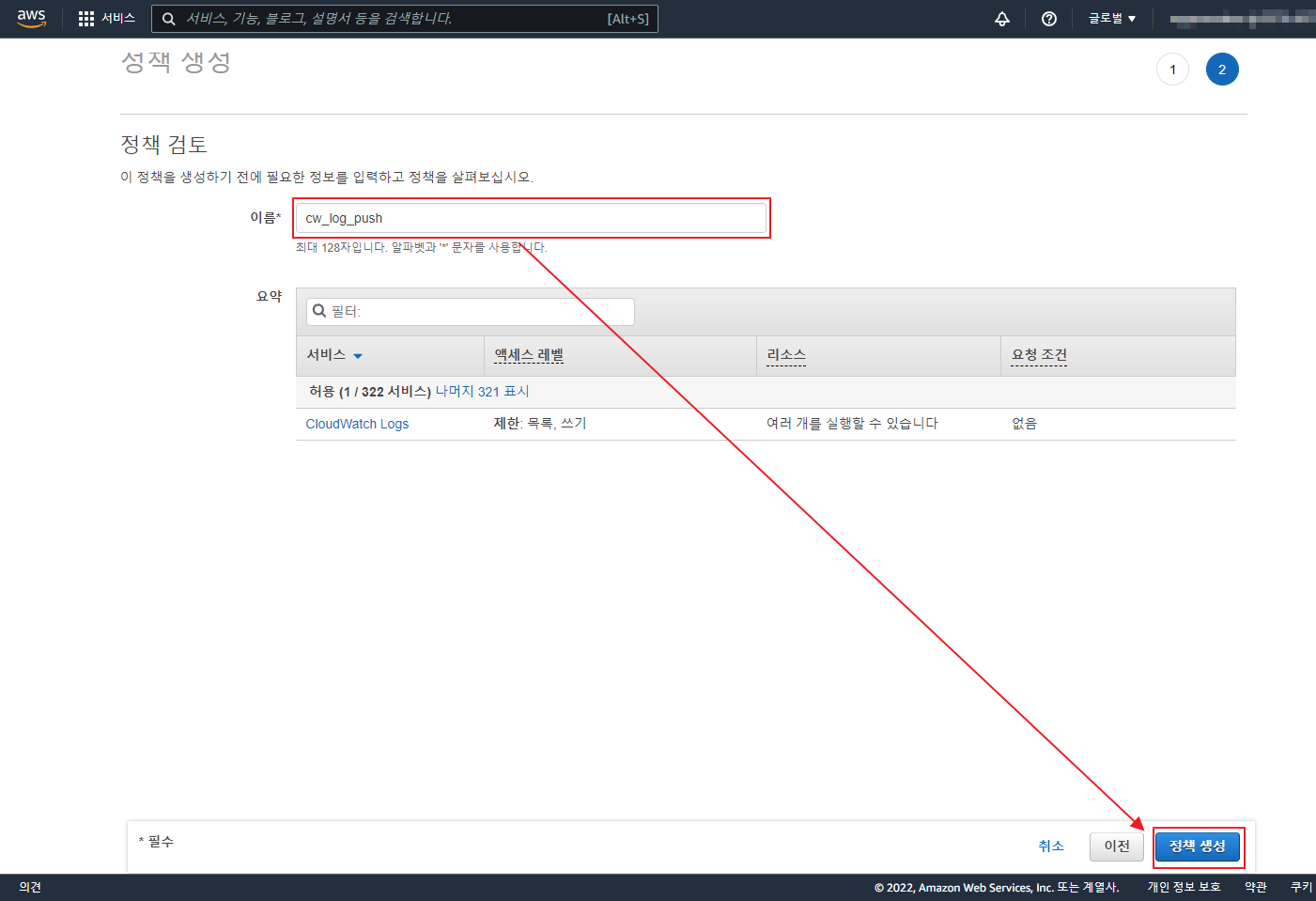
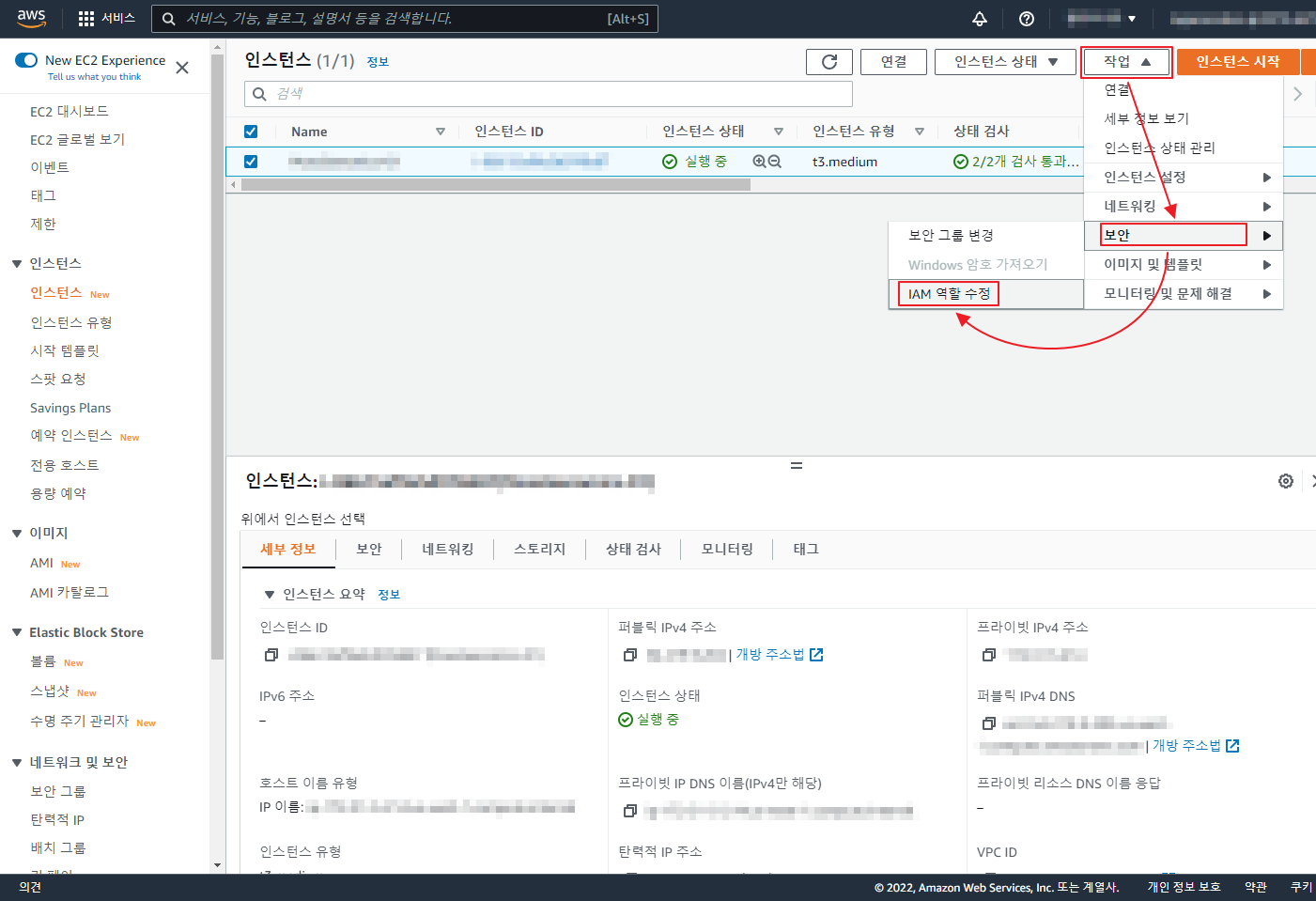
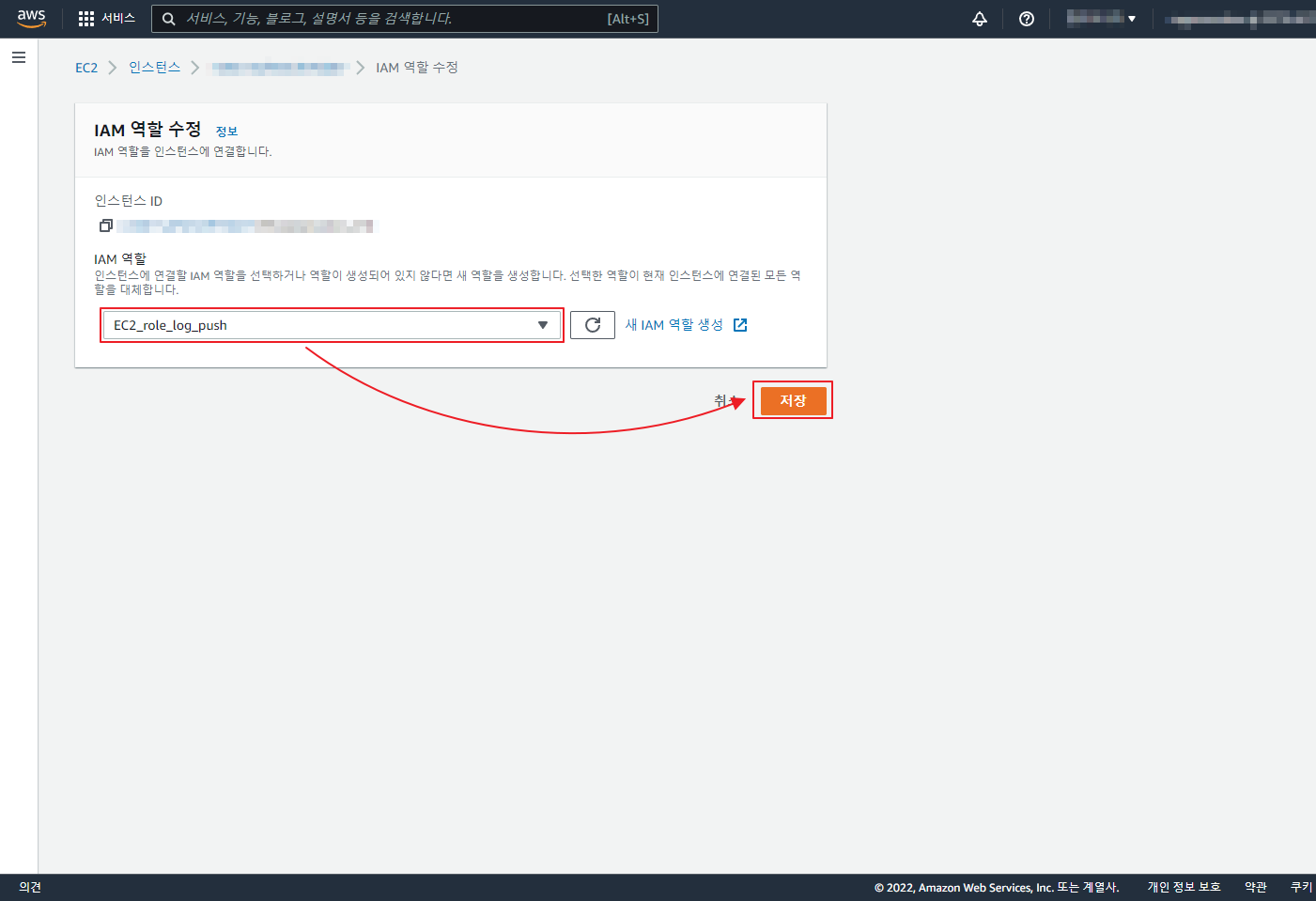
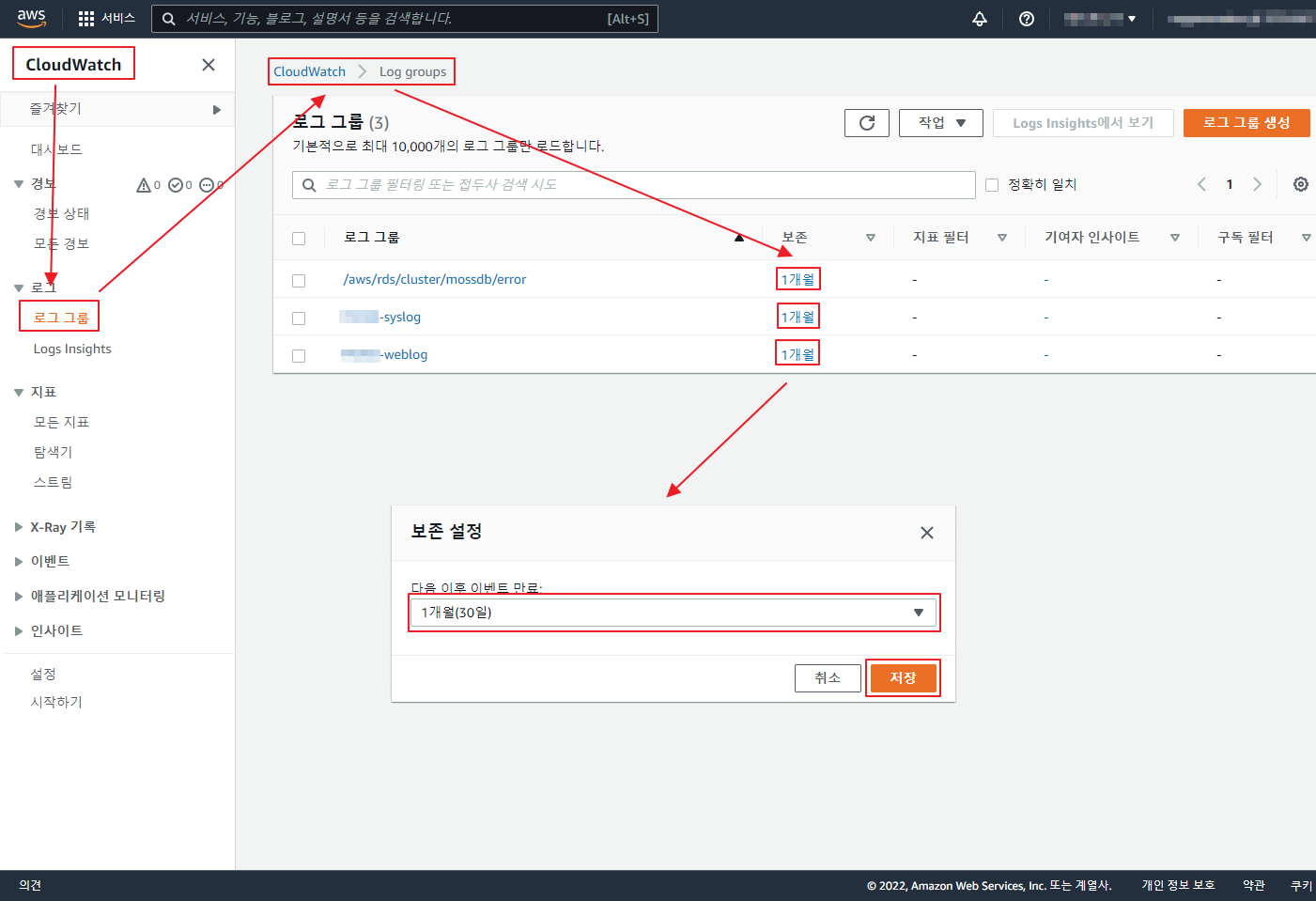
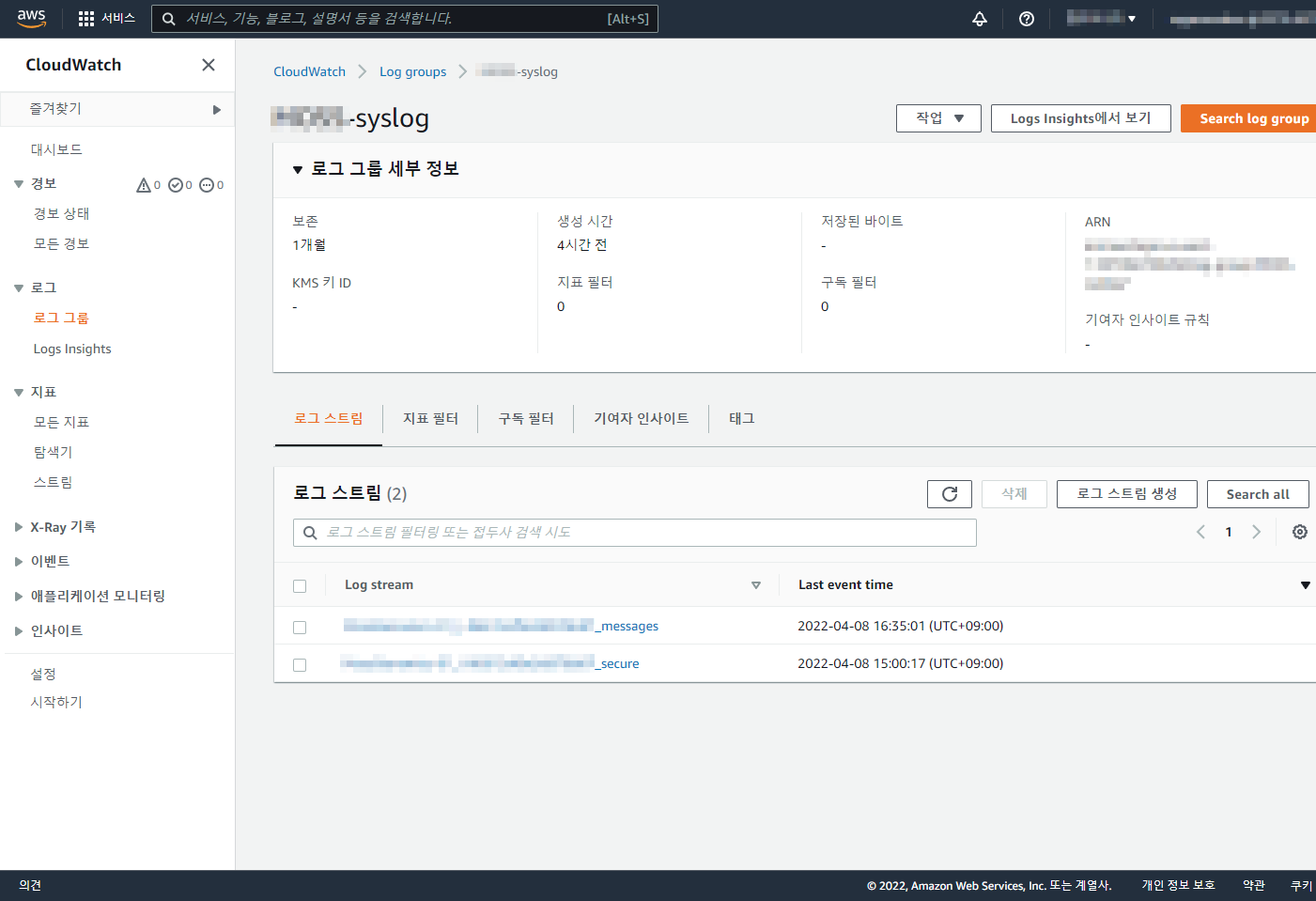
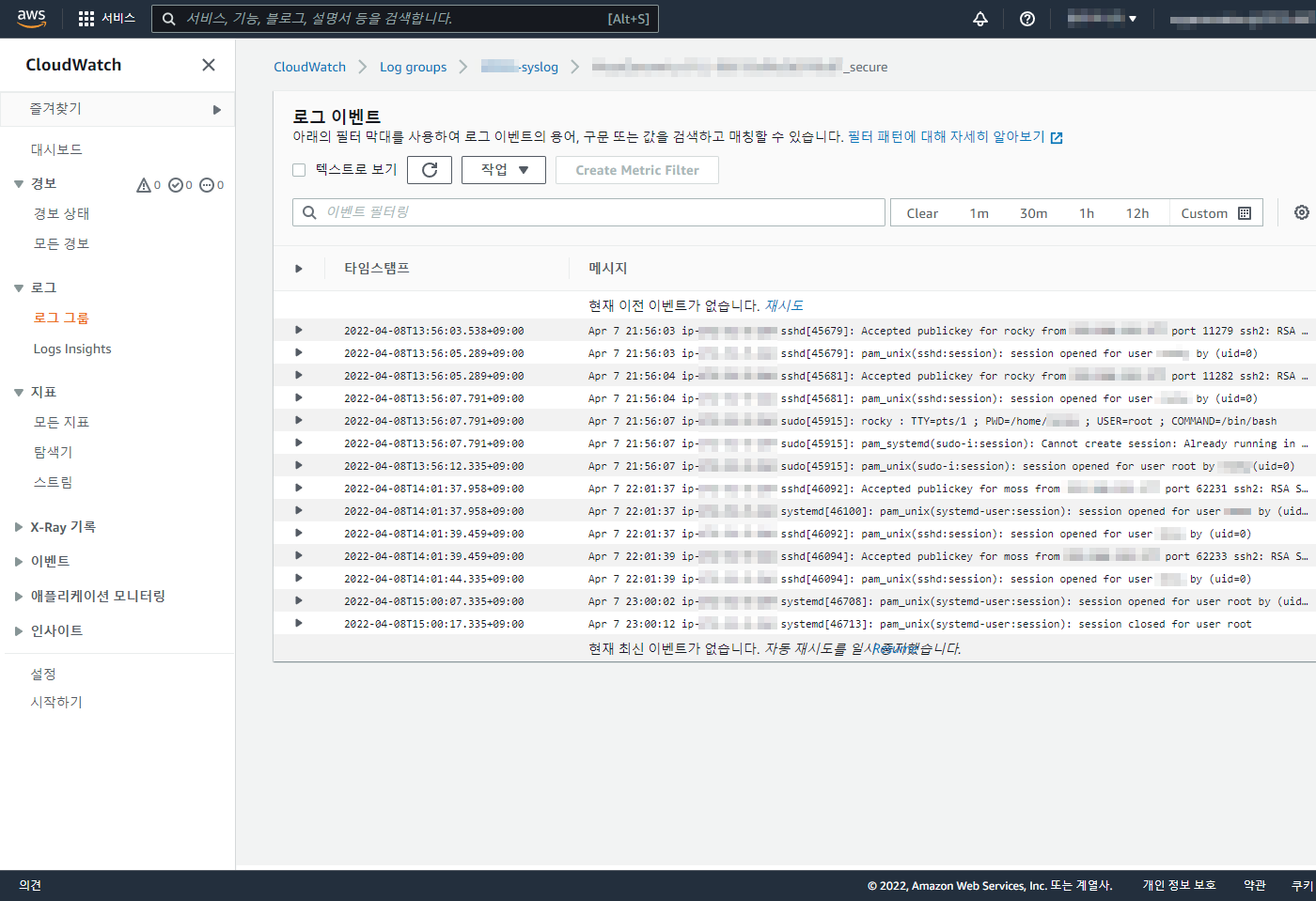
아래 글은 오래 되어 도커 이미지 등이 삭제 되었으니 공부 차원이 아니라 이용을 하려면 아래 확인 하세요 ‘ㅅ’a
오라클 클라우드의 무료 서버중 x86 서버인 VM.Standard.E2.1.Micro 의 경우 1/8 OCPU 및 1GB 메모리를 제공 한다.

1/8 OCPU 이는 cpu중 12% 점유율 사용량을 허용 한다는 말이다.
서버 내부에서는 2 논리 core 으로 확인 되기 때문에 각각의 cpu당 25% 의 점유율을 사용할 수 있다고 본다.
초과해서 사용할경우 과금 이 되거나 사용이 제한될 수 있는 요소이다.
메모리의 경우에는 dmesg 명령어로 아래와 같이 확인이 되었다.
|
1 2 |
~]# dmesg |grep memory [ 0.006919] Reserving 280MB of memory at 678MB for crashkernel (System RAM: 1018MB) |
즉 전체 용량 1018MB 에서 커널 보호를 위해 280MB 를 제외한 678MB를 쓸수 있다.
linux 커널에서 일반적으로 약 500MB정도를 사용한다고 보면 가용 메모리가 278MB 정도 밖에 되지 않는다.
쓰다보면 메모리가 swap 처리 되어서 WEB/WAS 사용가능한 메모리는 약 270~500MB 사이 정도가 될 것이다.
현재 블로그와 같이 구글 애드센스가 도입된 wordpress 사이트는 약 1.2초 대의 로딩 속도가 나오는 정도의 성능으로 확인되었다.
다만 방문객이 일정량 이상 늘어날 경우 급격히 느려지고, php-fpm이 메모리 과점으로 php-fpm 장애가 발생하는등의 문제가 발생 하였다.
그래서 ARM cpu 를 사용하는 VM.Standard.A1.Flex 를 이용해 was 서버를 운영하는 방법으로 구성을 해보았다.
아래는 OCI의 oracle linux 를 설치 했을때 기본적으로 진행해야 하는 명령어 모음 이다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# 타임존 설정 ~]# ln -sf /usr/share/zoneinfo/Asia/Seoul /etc/localtime # oracle-epel-release 활성화 (이부분은 oracle-epel-ol8.repo 에서 enabled=0 처리가 되어 있어서 하는 부분..) ~]# yum-config-manager --enable ol8_developer_EPEL ol8_developer_EPEL_modular # OS 업그레이드 ~]# dnf -y upgrade # 업그레이드 후 재부팅 ~]# reboot # 필수 프로그램 설치(sealert, htop, pstree) ~]# dnf install psmisc htop setools-console setroubleshoot-server # vim 사용 설정 ~]# echo "alias vi=vim" >> /etc/bashrc |
aarch64(ARM64) CPU를 사용 하는 경우 다음과 같은 문제가 있다.
- ARM64용 서드 파티 레포지토리는 거의 없는 편이다. (최신 php 버전을 제공 하는 remi 레포 또는 webtatic 등등)
- OS공식 레포지토리에서 제공 되는 httpd 버전은 2.4.37 버전 php 버전은 7.4.19 버전 이다.
- Let’s encrypt 에서 제공 되는 snapd(certbot) 이 동작을 하지 않는다. (x86_64 에서는 동작한다.)
위와 같은 사유로 3 티어 방식으로 운영이 되도록 구성 한다.
WAS 서버에 docker 에 amazon linux 2 (aarch64)를 이용 해서 apache + php-fpm 구성을 할 경우 최신 버전의 php 를 사용할 수 있고,
.htaccess 를 apache 문법으로 사용이 가능 하다는 장점이 있고, was 의 빠른 처리를 위한 갯수를 늘리거나 php 버전 교체도 쉬울 예정이기 때문에 채택 하였다.
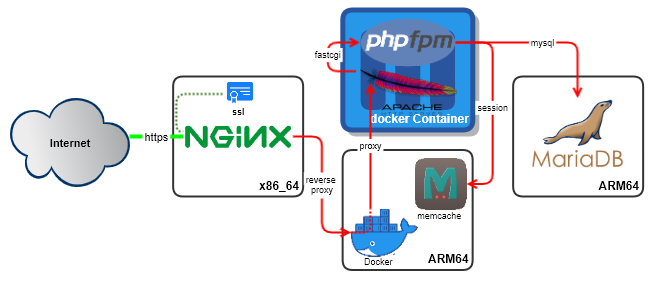
tier 1 = x86_64 – oracle linux 8 – nginx (Let’s encrypt SSL 구성 및 리버스프록시 설정)
tier 2 = arm64 – oracle linux 8 – memcache (session 적재 용도), docker – amazon linux – httpd, phpfpm(amazon linux 가 arm64 에서 최신 php 버전을 지원한다.)
tier 3 = arm64 – oracle linux 8 – mariadb
티어2 의 구성을 위해 ARM 인스턴스에 docker 레포지토리를 추가 하고, docker 와 memcache 를 설치 하고 활성화 한다.
|
1 2 3 4 5 |
~]# cd /etc/yum.repos.d ~]# curl https://download.docker.com/linux/centos/docker-ce.repo -O ~]# dnf install docker-ce docker-ce-cli containerd.io docker-compose-plugin memcached ~]# systemctl enable --now docker.service memcached.service |
위에서 언급 했지만 ARM64 cpu는 지원 하는 서드 파티 레포지토리가 없다.
AWS 에서 사용하는 Amazon Linux 2 의경우 내장된 명령어(repo) amazon-linux-extras 를 이용하여 최신 버전의 php 7.4 및 8.0 을 사용할 수 있다.
Amazon Linux 2 는 RHEL 또는 Fedora 와 같은 계열 이라고 볼 수 있다.
ARM64 서버에서 http 및 php를 구동하는 도커 이미지는 기존과 같은 방법으로 생성 하였다.
- 새로운 도커 이미지 : https://hub.docker.com/r/san0123/rocky9-http-php
docker 내부에서 apache 및 php-fpm 은 apache:apache 권한으로 작동을 하게 되어 있다.
아래와 같이 docker 호스트 서버에 apache 그룹 및 apache 유져를 생성 해두면 권한 문제가 맞추어 지기 때문에 퍼미션 지정이 필요 없어 진다.
|
1 2 3 4 5 |
~]# groupadd -g 48 apache ~]# useradd -s /sbin/nologin -u 48 -g apache -d /usr/share/httpd -c Apache apache ~]# mkdir -p /free/home/project/html ~]# chown -R apache:apache /free/home/project/html |
도커 프록시로 처리되어 http 포트를 firewall-cmd 명령어로 방화벽에 열 필요는 없지만 컨테이너 안에서 ARM 호스트 서버쪽으로 session 적재를 위해 접근 하기 때문에 방화벽을 허용 처리 한다.
|
1 2 |
~]# firewall-cmd --add-service=memcache --permanent ~]# firewall-cmd --reload |
도커 명령어를 이용해 컨테이너를 생성 한다.
|
1 2 |
~]# docker run -d --restart unless-stopped --add-host host.docker.internal:host-gateway \ -p 80:80 --mount type=bind,source=/free/home/project/html,target=/var/www/html san0123/rocky9-http-php:7.4 |
포트 매칭(:80) 및 볼륨 매칭(/free/home/project/html)을 해서 컨테이너는 생성 했기 때문에
docker 내부가 아닌 Oracle Linux 상의 /free/home/project/html 폴더로 이동 하여 아래의 내용과 같이 index.php 를 만들고 http(:80) 포트로 접속하여 확인 한다.
|
1 2 3 |
~]# cd /free/home/project/html ~]# vi index.php |
|
1 2 |
<?php phpinfo(); |
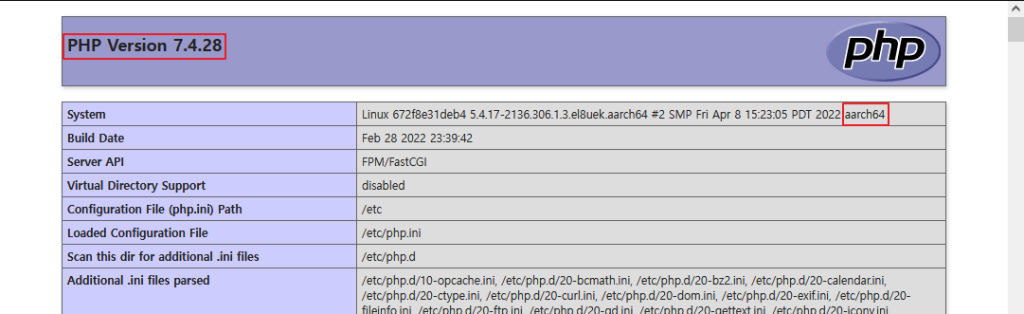
다음은 x86_64 인스턴스에 nginx 으로 Lets’encrypt 으로 보안서버 SSL 을 구현 하고
reverse proxy 를 해서 현재 was 서버 쪽으로 접속 시키는 부분이 남았다. (Tier 1)
하지만 was 서버도 apache를 가지고 있기 때문에 사이트를 단순히 구동 시키는건 가능 하다 ‘ㅅ’a
docker 를 만들때 httpd 가 생성 하는 로그는 stdout/stderr 으로 연결 해두었다.
이는 json 형태로 저장 되며 /var/lib/docker/containers/컨테이너풀아이디/컨테이너풀아이디-json.log 경로에 json 형태로 존재 한다.
명령어로 확인 하는 방법은 아래 방법으로 확인할 수 있다. [apache(httpd), php-fpm]
|
1 2 3 4 5 |
Apache 로그 확인 ~]# docker logs --tail=100 --follow 컨테이너 php-fpm 로그 확인 ~]# docker exec -it 컨테이너 tail -100f /var/log/php-fpm/www-error.log |
아래는 위에서 pull 받은 도커이미지를 구축할때 사용된 Dockerfile 이다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
FROM amazonlinux:latest MAINTAINER Enteroa <enteroa@kakao.com> version: demonize RUN amazon-linux-extras enable php7.4 &&\ yum -y install httpd php-cli php-pdo php-fpm php-json php-mysqlnd php-bcmath php-gd php-intl php-mbstring php-opcache php-pear php-soap php-xml php-pecl-memcached &&\ yum clean all &&\ sed -i 's+^post_max_size = 8M+post_max_size = 120M+g;s+^upload_max_filesize = 2M+upload_max_filesize = 100M+g;s+^short_open_tag = Off+short_open_tag = On+g;s+;mysqli.allow_local_infile = On+mysqli.allow_local_infile = On+g;s+^expose_php = On+expose_php = Off+g' /etc/php.ini &&\ sed -i 's+pid = /run/php-fpm/php-fpm.pid+pid = /run/httpd/php-fpm.pid+g' /etc/php-fpm.conf &&\ sed -i 's+listen = /run/php-fpm/www.sock+listen = 9000+g;s+^php_value\[session.save_handler\] = files+php_value[session.save_handler] = memcached+g;s+^php_value\[session.save_path\] = /var/lib/php/session+php_value[session.save_path] = "host.docker.internal:11211"+g' /etc/php-fpm.d/www.conf &&\ sed -i 's+SetHandler "proxy:unix:/run/php-fpm/www.sock|fcgi://localhost"+SetHandler "proxy:fcgi://127.0.0.1:9000"+g' /etc/httpd/conf.d/php.conf &&\ sed -i 's+UserDir disabled+UserDir html+g;s+tory "/home/\*/public_html">+tory "/var/www/html">+g' /etc/httpd/conf.d/userdir.conf &&\ sed -i 's+^LoadModule mpm_prefork_module modules/mod_mpm_prefork.so+#LoadModule mpm_prefork_module modules/mod_mpm_prefork.so+g;s+^#LoadModule mpm_event_module modules/mod_mpm_event.so+LoadModule mpm_event_module modules/mod_mpm_event.so+g' /etc/httpd/conf.modules.d/00-mpm.conf &&\ echo "RemoteIPHeader X-Forwarded-For" >> /etc/httpd/conf/httpd.conf && echo "RemoteIPTrustedProxy 10.0.0.1/24" >> /etc/httpd/conf/httpd.conf &&\ DOTHT_NUM=$(grep -n '^<Files ".ht' /etc/httpd/conf/httpd.conf | awk -F: '{print $1+1}') \ sed -i "${DOTHT_NUM}s+Require all denied+Require all granted+g;s+#ServerName www.example.com:80+ServerName localhost+g" /etc/httpd/conf/httpd.conf &&\ ln -sf /dev/stdout /var/log/httpd/access_log && ln -sf /dev/stderr /var/log/httpd/error_log WORKDIR /var/www/html EXPOSE 80 ENTRYPOINT ["/bin/sh", "-c" , "/usr/sbin/php-fpm -D && /usr/sbin/httpd -D FOREGROUND"] |