기존 v 2.2.9 엄청나게 많은 부분이 바뀌었다. ( 초급자에게 오히려 다루기가 쉬워졌다. )
기존 CRS 를 쓰던 사람은 v3.0.0 으로 업그레이드 하지 말고 새롭게 설치해야 한다.
– 설치 방법은 apache 기준이다. Nginx, IIS 의 경우 포함된 INSTALL 문서를 참조하여 설치해야 한다.
물론 기존에도 spamhouse 연동이나 spam bot의 에이젼트 구분을 하던부분이 있었지만.
projecthoneypot.org 연동으로 기존 룰셋에 비해 스팸 방지 기능이 매우 탁월해 졌다.
– Blocking Based on IP Reputation 부분을 정독하고 SecHttpBlKey 를 연동해야한다.
- git을 이용하여 룰셋 다운로드를 하고 기초 메뉴얼에 따라 파일 명 변경등을 한다.
|
1 2 3 4 5 6 |
~]# cd /usr/local/apache/conf ~]# git clone https://github.com/SpiderLabs/owasp-modsecurity-crs.git ~]# cd owasp-modsecurity-crs ~]# mv crs-setup.conf.example crs-setup.conf ~]# mv rules/REQUEST-900-EXCLUSION-RULES-BEFORE-CRS.conf.example rules/REQUEST-900-EXCLUSION-RULES-BEFORE-CRS.conf ~]# mv rules/RESPONSE-999-EXCLUSION-RULES-AFTER-CRS.conf.example rules/RESPONSE-999-EXCLUSION-RULES-AFTER-CRS.conf |
- httpd.conf 에서 아래와 같이 각 룰셋 등을 불러오도록 설정한다.
|
1 2 3 4 |
<IfModule security2_module> Include conf/owasp-modsecurity-crs/crs-setup.conf Include conf/owasp-modsecurity-crs/rules/*.conf </IfModule> |
- 이후 crs-setup.conf 수정을 한다. ( 사랑해요 구글 번역♥ )
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 |
# ------------------------------------------------------------------------ # OWASP ModSecurity Core Rule Set ver.3.0.0 # Copyright (c) 2006-2016 Trustwave and contributors. All rights reserved. # # The OWASP ModSecurity Core Rule Set is distributed under # Apache Software License (ASL) version 2 # Please see the enclosed LICENSE file for full details. SecRuleEngine On SecRequestBodyAccess On SecResponseBodyAccess On SecRequestBodyLimit 13107200 SecRequestBodyNoFilesLimit 131072 SecRequestBodyInMemoryLimit 131072 SecRequestBodyLimitAction Reject SecPcreMatchLimit 150000 SecPcreMatchLimitRecursion 150000 SecResponseBodyMimeType text/plain text/html text/xml SecResponseBodyLimit 2097152 SecResponseBodyLimitAction ProcessPartial SecTmpDir /tmp SecDataDir /tmp ErrorDocument 406 "REQUEST or RESPONSE data have Security Issue" SecDefaultAction "phase:1,log,noauditlog,deny,status:406" SecDefaultAction "phase:2,log,noauditlog,deny,status:406" # -- [[ Paranoia Level Initialization ]] --------------------------------------- # 편집증 수준 (PL) 설정을 사용하면 원하는 수준의 규칙 검사를 선택할 수 있습니다. # # - 편집증 수준 1이 기본값입니다. 이 수준에서는 대부분의 핵심 규칙이 사용됩니다. PL1은 초보자, # 다양한 사이트 및 응용 프로그램을 포함하는 설치 및 표준 보안 요구 사항이있는 설치에 대해 권장됩니다. # PL1에서 FP를 거의 접하지 않아야합니다. # FP가 발생하면 CRS GitHub 사이트에서 문제를 열고 문제와 함께 요청에 대한 전체 감사 로그 레코드를 첨부하는 것을 잊지 마십시오. # # - 편집증 수준 2에는 많은 추가 규칙이 포함되어 있습니다. # 예를 들어 많은 정규 표현식 기반 SQL 및 XSS 삽입 방지를 사용하고 코드 삽입을 위해 추가 키워드를 추가하는 등의 # 추가 규칙이 있습니다. PL2는보다 완벽한 커버리지를 원하는 중급에서 고급 사용자와 높은 보안 요구 사항이있는 설치에 권장됩니다. # PL2에는 처리해야 할 FP가 있습니다. # # - 편집증 수준 3은 더 많은 규칙과 키워드 목록을 사용하고 특수 문자 사용 제한을 조정합니다. # PL3은 보안 요구 사항이 높은 설치 및 FP를 처리하는 데 익숙한 사용자를 대상으로합니다. # # - 편집증 레벨 4는 특수 문자를 더 제한합니다. # 가장 높은 수준은 보안 요구 사항이 매우 높은 설치를 보호하는 숙련 된 사용자에게 권장됩니다. # PL4를 실행하면 매우 많은 수의 FP가 생성되어 현장에서 생산성을 높일 수 있습니다. SecAction "id:900000, phase:1, nolog, pass, t:none, setvar:tx.paranoia_level=1" # -- [[ Anomaly Mode Severity Levels ]] ---------------------------------------- # CRS의 각 규칙에는 연관된 심각도 수준이 있습니다. # 각 심각도 수준의 기본 점수 점입니다. # 이 설정은 규칙이 일치하는 경우 예외 점수를 증가시키는 데 사용됩니다. # 이 포인트는 원하는대로 조정할 수 있지만 대개는 필요하지 않습니다. # - CRITICAL severity: Anomaly Score of 5. Mostly generated by the application attack rules (93x and 94x files). # - ERROR severity: Anomaly Score of 4. Generated mostly from outbound leakage rules (95x files). # - WARNING severity: Anomaly Score of 3. Generated mostly by malicious client rules (91x files). # - NOTICE severity: Anomaly Score of 2. Generated mostly by the protocol rules (92x files). # 비정상 모드에서이 점수는 누적됩니다. 요청이 여러 규칙에 부딪 힐 수 있습니다. SecAction "id:900100, phase:1, nolog, pass, t:none, setvar:tx.critical_anomaly_score=5, setvar:tx.error_anomaly_score=4,\ setvar:tx.warning_anomaly_score=3, setvar:tx.notice_anomaly_score=2" # -- [[ Anomaly Mode Blocking Threshold Levels ]] ------------------------------ # 여기서 인바운드 요청 또는 아웃 바운드 응답이 차단 된 누적 이상 점수를 지정할 수 있습니다. # 가장 많이 발견 된 인바운드 위협은 5 점을받습니다. 프로토콜 / 표준 위반과 같은 위반이 적 으면 점수가 낮아집니다. # # [ Anomaly Threshold / Paranoia Level Quadrant ] # High Anomaly Limit | High Anomaly Limit # Low Paranoia Level | High Paranoia Level # -> Fresh Site | -> Experimental Site # ------------------------------------------------------ # Low Anomaly Limit | Low Anomaly Limit # Low Paranoia Level | High Paranoia Level # -> Standard Site | -> High Security Site # SecAction "id:900110, phase:1, nolog, pass, t:none,\ setvar:tx.inbound_anomaly_score_threshold=5, setvar:tx.outbound_anomaly_score_threshold=4" # -- [[ Application Specific Rule Exclusions ]] ---------------------------------------- # 잘 알려진 일부 응용 프로그램은 악의적 인 것으로 보이는 작업을 수행 할 수 있습니다. # 여기에는 매개 변수 내에서 HTML 또는 Javascript를 허용하는 것과 같은 작업이 포함됩니다. # 이러한 경우 CRS는 관리자가 응용 프로그램별로 응용 프로그램에 대해 미리 작성된 # 응용 프로그램 별 예외를 활성화 할 수 있도록하여 오탐 (false positive)을 방지하는 것을 목표로합니다. # # 이 응용 프로그램 특정 제외는 REQUEST-900-EXCLUSION-RULES-BEFORE-CRS 구성 파일에있는 규칙과는 다른데, # 이는 특정 응용 프로그램에 대해 미리 작성되어 있기 때문입니다. # 'REQUEST-900'파일은 사용자가 자신의 사용자 지정 제외 항목을 추가 할 수 있도록 설계되었습니다. # 이러한 애플리케이션 별 제외 사항을 사용하면 CRS의 제한 사항이 완화 될 수 있습니다. # 특히 CRS가 설계되지 않은 애플리케이션과 함께 사용되는 경우 더욱 그렇습니다. 결과적으로 그들은주의를 기울여 적용해야합니다. # # 이 기능을 사용하려면 지원되는 응용 프로그램을 지정해야합니다. # 규칙 900130의 주석 처리를 제거하려면 다음을 수행하십시오. # 룰의 주석 처리 이외에 제외를 사용하려는 어플리케이션을 지정해야합니다. # 현재 (매우) 제한된 응용 프로그램 집합 만 지원됩니다. # 'REQUEST-903'이라는 접두어가 붙은 파일 이름을 사용하여 선택을 안내하십시오. # 이러한 파일 이름은 다음 규칙을 사용합니다. # REQUEST-903.9XXX-{APPNAME}-EXCLUSIONS-RULES.conf # # 다음 예제와 비슷한 규칙을 사용하여 제외 된 웹 응용 프로그램이있는 경로에만 제외 효과를 제한하려면 # 사이트에서 여러 웹 응용 프로그램을 실행하는 것이 좋습니다. # SecRule REQUEST_URI "@beginsWith / wordpress /"setvar : crs_exclusions_wordpress = 1 # SecAction "id:900130, phase:1, nolog, pass, t:none,\ setvar:tx.crs_exclusions_drupal=1, setvar:tx.crs_exclusions_wordpress=1" # -- [[ HTTP Policy Settings ]] ------------------------------------------------ # 이 섹션에서는 다음과 같은 HTTP 프로토콜에 대한 정책을 정의합니다. # - 허용 된 HTTP 버전, HTTP 메소드, 허용 된 요청 Content-Types # - 금지 된 파일 확장명 (예 : .bak, .sql) 및 요청 헤더 (예 : 프록시) SecAction "id:900200, phase:1, nolog, pass, t:none, setvar:'tx.allowed_methods=GET HEAD POST OPTIONS'" SecAction "id:900220, phase:1, nolog, pass, t:none,\ setvar:'tx.allowed_request_content_type=application/x-www-form-urlencoded|multipart/form-data|text/xml|application/xml|application/x-amf|application/json|text/plain'" SecAction "id:900230, phase:1, nolog, pass, t:none, setvar:'tx.allowed_http_versions=HTTP/1.0 HTTP/1.1 HTTP/2 HTTP/2.0'" SecAction "id:900240, phase:1, nolog, pass, t:none,\ setvar:'tx.restricted_extensions=.asa/ .asax/ .ascx/ .axd/ .backup/ .bak/ .bat/ .cdx/ .cer/ .cfg/ .cmd/ .com/ .config/ .conf/ .cs/ .csproj/ .csr/ .dat/ .db/ .dbf/ .dll/ .dos/ .htr/ .htw/ .ida/ .idc/ .idq/ .inc/ .ini/ .key/ .licx/ .lnk/ .log/ .mdb/ .old/ .pass/ .pdb/ .pol/ .printer/ .pwd/ .resources/ .resx/ .sql/ .sys/ .vb/ .vbs/ .vbproj/ .vsdisco/ .webinfo/ .xsd/ .xsx/'" SecAction "id:900250, phase:1, nolog, pass, t:none,\ setvar:'tx.restricted_headers=/proxy/ /lock-token/ /content-range/ /translate/ /if/'" SecAction "id:900260, phase:1, nolog, pass, t:none,\ setvar:'tx.static_extensions=/.jpg/ /.jpeg/ /.png/ /.gif/ /.js/ /.css/ /.ico/ /.svg/ /.webp/'" # -- [[ HTTP Argument/Upload Limits ]] ----------------------------------------- # 여기서 HTTP get / post 매개 변수 및 업로드에 대한 선택적 제한을 정의 할 수 있습니다. # 이것은 응용 프로그램 특정 DoS 공격을 방지하는 데 도움이 될 수 있습니다. # 이 값은 REQUEST-920-PROTOCOL-ENFORCEMENT.conf에서 확인합니다. # 이러한 제한을 사용할 때 합법적 인 트래픽 차단에주의하십시오. #SecAction "id:900300, phase:1, nolog, pass, t:none, setvar:tx.max_num_args=255" #SecAction "id:900310, phase:1, nolog, pass, t:none, setvar:tx.arg_name_length=100" #SecAction "id:900320, phase:1, nolog, pass, t:none, setvar:tx.arg_length=400" #SecAction "id:900330, phase:1, nolog, pass, t:none, setvar:tx.total_arg_length=64000" #SecAction "id:900340, phase:1, nolog, pass, t:none, setvar:tx.max_file_size=1048576" #SecAction "id:900350, phase:1, nolog, pass, t:none, setvar:tx.combined_file_sizes=1048576" # -- [[ Easing In / Sampling Percentage ]] ------------------------------------- # 핵심 규칙 집합을 기존의 생산 사이트에 추가하면 오 탐지, 예기치 않은 성능 문제 및 기타 원하지 않는 부작용이 발생할 수 있습니다. # # 제한된 수의 요청에 대해서만 CRS를 사용하도록 설정 한 다음 문제가있는 경우 CRS를 설정하고 # 설정에 대한 확신이있는 경우 CRS를 보내서 물을 테스트하는 것이 유용 할 수 있습니다. 규칙 집합에 추가합니다. # # 아래에서 TX.sampling_percentage를 설정하여 핵심 규칙에 유입되는 요청의 비율을 조정합니다. # 기본값은 100입니다. 즉, 모든 요청이 CRS에 의해 검사됩니다. # 검사 될 요청의 선택은 ModSecurity에 의해 생성 된 의사 랜덤 번호를 기반으로합니다. # # 요청이 CRS에 의해 검사되지 않고 통과 할 수 있으면 성능상의 이유로 감사 로그에 항목이 없지만 오류 로그 항목이 기록됩니다. # 오류 로그 항목을 비활성화하려면 CRS가 포함 된 후 어딘가에서 다음 지시문을 실행하십시오 # (E.g., RESPONSE-999-EXCEPTIONS.conf) # # SecRuleUpdateActionById 901150 "nolog" # # 주의 :이 TX.sampling_percentage가 100 미만이면 요청 중 일부가 핵심 규칙을 완전히 무시하고 # ModSecurity로 서비스를 보호 할 수 없게됩니다. # #이 기능을 사용하려면이 규칙의 주석을 해제하십시오. SecAction "id:900400, phase:1, pass, nolog, setvar:tx.sampling_percentage=100" # -- [[ Project Honey Pot HTTP Blacklist ]] ------------------------------------ # 필요에 따라 클라이언트 IP 주소를 Project Honey Pot HTTPBL (dnsbl.httpbl.org)과 비교하여 확인할 수 있습니다. # 이를 사용하려면 무료 API 키를 받으려면 등록해야합니다. 여기에 SecHttpBlKey로 설정하십시오. # # Project Honeypot은 여러 가지 다양한 악성 IP 유형을 반환합니다. # 아래에서 활성화 또는 비활성화하여 차단할 항목을 지정할 수 있습니다. # Ref: https://www.projecthoneypot.org/httpbl.php # Ref: https://github.com/SpiderLabs/ModSecurity/wiki/Reference-Manual#wiki-SecHttpBlKey SecHttpBlKey XXXXXXXXXXXX SecAction "id:900500, phase:1, nolog, pass, t:none, setvar:tx.block_search_ip=1, setvar:tx.block_suspicious_ip=1,\ setvar:tx.block_harvester_ip=1, setvar:tx.block_spammer_ip=1" # -- [[ GeoIP Database ]] ------------------------------------------------------ #SecGeoLookupDB /var/geoip/GeoIP.dat # -=[ Block Countries ]=- #SecAction "id:900600, phase:1, nolog, pass, t:none, setvar:'tx.high_risk_country_codes='" # -- [[ Anti-Automation / DoS Protection ]] ------------------------------------ # 요청을 너무 빨리 만드는 클라이언트에 대한 선택적 DoS 보호. # # 클라이언트가 60 초 이내에 100 개가 넘는 요청 (정적 파일 제외)을 수행하는 경우 # 이는 '버스트 (burst)'로 간주됩니다. 두 번 터지면 클라이언트는 600 초 동안 차단됩니다. # # 정적 파일에 대한 요청은 DoS에 포함되지 않습니다. # 이 파일에서 변경할 수있는 'tx.static_extensions'설정에 나열되어 있습니다 ( "HTTP 정책 설정"절 참조). # # 자세한 설명은 룰 파일 REQUEST-912-DOS-PROTECTION.conf를 참조하십시오. SecAction "id:900700, phase:1, nolog, pass, t:none, setvar:'tx.dos_burst_time_slice=60', setvar:'tx.dos_counter_threshold=300',\ setvar:'tx.dos_block_timeout=600'" # -- [[ Check UTF-8 encoding ]] ------------------------------------------------ #SecAction "id:900950, phase:1, nolog, pass, t:none, setvar:tx.crs_validate_utf8_encoding=1" # -- [[ Blocking Based on IP Reputation ]] ------------------------------------ # 평판에 근거한 차단은 CRS에서 영구적입니다. # 개별 요청을 보는 다른 규칙과 달리 IP 차단은 IP 수집의 지속적인 레코드를 기반으로하며 # 일정 기간 동안 활성 상태로 유지됩니다. # # 개별 클라이언트가 차단을 위해 플래그가 지정되는 두 가지 방법이 있습니다. # - External information (RBL, GeoIP, etc.) # - Internal information (Core Rules) # # IP 컬렉션의 레코드는 IP.reput_block_flag라는 플래그로 개별 클라이언트의 요청에 # 태그를 지정하는 플래그를 전달합니다. 그러나 플래그만으로는 클라이언트를 차단할 수 없습니다. # 또한 tx.do_reput_block이라는 전역 스위치가 있습니다. # 기본적으로 해제되어 있습니다. 1 (= On)으로 설정하면 # IP.reput_block_flag가있는 클라이언트의 요청이 일정 기간 동안 차단됩니다. # # Variables # ip.reput_block_flag IP 수집 레코드의 차단 플래그 # ip.reput_block_reason 플래그를 차단하는 이유 (= 규칙 메시지) # tx.do_reput_block 플래그에 따라 실제로 차단할지 결정합니다. # tx.reput_block_duration 블록 기간을 정의하는 설정 # # 문제의 블로킹 플래그를 가지고 있다는 것이 명백 할 때 다른 모든 핵심 규칙은 요청을 # 건너 뛰는 것을 아는 것이 중요 할 수 있습니다. SecAction "id:900960, phase:1, nolog, pass, t:none, setvar:tx.do_reput_block=1" SecAction "id:900970, phase:1, nolog, pass, t:none, setvar:tx.reput_block_duration=300" # -- [[ Collection timeout ]] -------------------------------------------------- # SecCollectionTimeout 지시문을 ModSecurity 기본값 (1 시간)에서 대부분의 사이트에 적합한 낮은 설정으로 설정하십시오. # 오래된 콜렉션 (블록) 항목을 제거하여 성능을 향상시킵니다. # 이 값은 다음보다 커야합니다. # tx.reput_block_duration (see section "Blocking Based on IP Reputation") and # tx.dos_block_timeout (see section "Anti-Automation / DoS Protection"). SecCollectionTimeout 600 # -- [[ Debug Mode ]] ---------------------------------------------------------- # 규칙 개발 및 디버깅을 사용하기 위해 CRS에는 요청을 차단하지 않고 # HTTP 클라이언트에 검색 정보를 다시 보내는 선택적 디버그 모드가 있습니다. # 이 기능은 현재 Apache 웹 서버에서만 지원됩니다. Apache mod_headers 모듈이 필요합니다. # 디버그 모드에서 웹 서버는 디버그 클라이언트가 요청할 때마다 "X-WAF-Events"/ "X-WAF-Score"응답 헤더를 삽입합니다. 예: # curl -v 'http://192.168.1.100/?foo=../etc/passwd' # X-WAF-Events: TX:930110-OWASP_CRS/WEB_ATTACK/DIR_TRAVERSAL-REQUEST_URI, # TX:930120-OWASP_CRS/WEB_ATTACK/FILE_INJECTION-ARGS:foo, # TX:932160-OWASP_CRS/WEB_ATTACK/RCE-ARGS:foo # X-WAF-Score: Total=15; sqli=0; xss=0; rfi=0; lfi=10; rce=5; php=0; http=0; ses=0 #Include /usr/local/apache/conf/owasp-modsecurity-crs/util/debug/RESPONSE-981-DEBUG.conf #SecRule REMOTE_ADDR "@ipMatch 192.168.1.100" "id:900980, phase:1, nolog, pass, t:none, ctl:ruleEngine=DetectionOnly,\ # setvar:tx.crs_debug_mode=1" # -- [[ End of setup ]] -------------------------------------------------------- # CRS는 tx.crs_setup_version 변수를 검사하여 설치 프로그램이로드되었는지 확인합니다. # 이 설정 템플릿을 사용하지 않으려면 CRS 규칙 / * 파일을 포함하기 전에 # tx.crs_setup_version 변수를 수동으로 설정해야합니다. # # 변수는 CRS 버전 번호의 숫자 표현입니다. # 예 : v3.0.0은 300으로 표시됩니다. SecAction "id:900990, phase:1, nolog, pass, t:none, setvar:tx.crs_setup_version=300" |
conf 파일중 “Project Honey Pot HTTP Blacklist” 부분은 제공되는 URL을 참조하여 SecHttpBlKey 키를 받아 사용한다.
https://www.projecthoneypot.org 을 접속 한 뒤에 회원 가입 및 메일 인증을 한뒤에 간단히 키를 받을 수 있다.
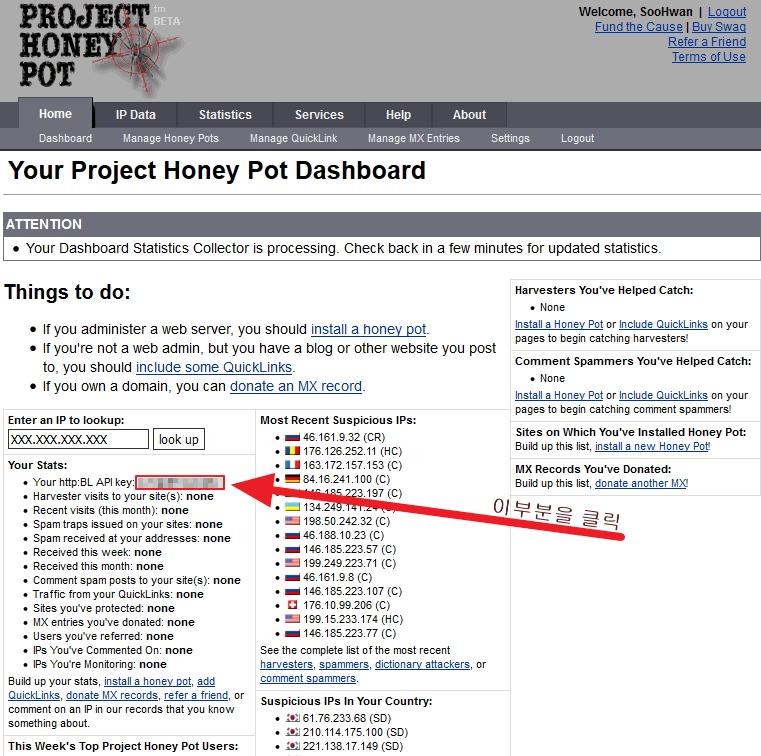
기초적인 crs-setup 이다 좀더 고급적인 설정을 하려면 하나하나 읽어보고 세팅해야한다 ‘ㅅ’a
Paranoia Level Initialization 선언을 1 이나 2 정도로 하는것이 좋을것으로 생각되며
현재 올려둔 기본 세팅 설정은 level = 1 이다.
- 룰셋 예외 처리
사전 룰셋 예외처리는 rules/REQUEST-900-EXCLUSION-RULES-BEFORE-CRS.conf 에서 선언된다.
|
1 2 3 |
### Localhost에서 접근시 엔진 Off ### SecRule REMOTE_ADDR "@ipMatch 222.22.222.1" "phase:1,id:1000,pass,nolog,ctl:ruleEngine=Off" SecRule REMOTE_ADDR "@ipMatch 127.0.0.1" "phase:1,id:1001,pass,nolog,ctl:ruleEngine=Off" |
주의할점은 여러줄을 선언할 경우 id:1000 그다음을 id:1001 이런식으로 틀리게 줘야 한다.
사후 룰셋 예외 처리는 rules/RESPONSE-999-EXCLUSION-RULES-AFTER-CRS.conf 에서 선언이 된다.
|
1 2 |
### 검색엔진 블럭 해제(Project Honeypot) ### SecRuleRemoveById 910150 |
Project Honey Pot HTTP Blacklist 에서 구글 봇의 접속조차 막기 때문에 추가 해서 운영하자 ‘ㅅ’a
기존 과 같이 가상호스트 내에서 특정 룰셋만 끄는것 역시 유효 하다.
|
1 2 3 4 5 6 7 |
<VirtualHost *:80> SecRuleRemoveById 942100 DocumentRoot /free/home/아이디/html ServerName 도메인.com ServerAlias 도메인.com www.도메인.com RUidGid 아이디 아이디 </VirtualHost> |
PS.1 여기까지 읽기전에 httpd.conf 에서 OWASP csr 룰셋을 불러오는 설정이 httpd-vhost.conf 혹은
httpd-ssl.conf 보다 먼저 불러와야 한다는걸 눈치챘다면…….. 참 잘했어요 🙂
PS.2 apache 2.4.11 보다 낮은 버전의 경우 SecRule 선언을 제대로 인식하지 않을 수 있다.
이때는 아래 명령어로 여러줄로 되어 있는 Rule 선언을 한줄로 만들어 줘야 한다.
|
1 |
~]# util/join-multiline-rules/join.py rules/*.conf > rules/rules.conf.joined |
PS.3 아래 명령어로 현재 modscurity 로직에 걸린 error_log 를 확인할 수 있다. IP ruleID URL/URI 가 출력된다.
룰셋 910000 910160 910170 의 경우 악의적인 / 의심되는 / 스패머 IP로 분류되는 것으로 제외하고 본다.
|
1 2 |
~]# cd /usr/local/apache/logs ~]# grep ModSecurity error_log|grep -Ev '910000|910160|910170'|sed -e 's#^.*client \([0-9.]*\).*\[id "\([0-9]*\).*hostname "\([a-z0-9A-Z.-_]*\)"\].*uri "#\1\t\2\t\3#'|cut -d\" -f1 |