말로만 듣지 말고 해보자 라는 개념으로 시작했다.
Anaconda3 64비트를 설치 하고 파이선의 venv를 생성 한뒤에 tensorflow 설치 및 keras 설치를 진행 한다.
|
1 2 3 4 |
C:\somewhere> set CONDA_FORCE_32BIT= C:\somewhere> conda create -n py38_64_ml_test C:\somewhere> activate py38_64_ml_test C:\somewhere> pip install numpy pandas matplotlib sklearn tensorflow==2.3.0 keras==2.4.3 |
이후 메뉴얼의 트레이닝을 했을때 CPU 연산을 하는것으로 확인이 되었고
연습용 PC 으로 AMD 르누아르 계열을 쓰고 있기 때문에 GPU 연산을 위해 PlaidML 을 설치 진행 하였다.
|
1 2 3 4 |
C:\somewhere> activate py38_64_ml_test C:\somewhere> pip install plaidml C:\somewhere> plaidml-setup |
setup시 대화형인데 동의, 그래픽카드선택, 저장 에 순서 의다.
사용방법 – keras를 이용하는 코드에서 아래와 같이 선언만 하면 된다.
|
1 2 |
import plaidml.keras plaidml.keras.install_backend() |
테스트1 – plaidbench
|
1 2 3 4 |
C:\somewhere> activate py38_64_ml_test C:\somewhere> pip install plaidml-keras plaidbench C:\somewhere> plaidbench keras mobilenet |
테스트2 – python 코드 VGG19
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
#!/usr/bin/env python import numpy as np import time import plaidml.keras plaidml.keras.install_backend() import keras import keras.applications as kapp from keras.datasets import cifar10 (x_train, y_train_cats), (x_test, y_test_cats) = cifar10.load_data() batch_size = 8 x_train = x_train[:batch_size] x_train = np.repeat(np.repeat(x_train, 7, axis=1), 7, axis=2) model = kapp.VGG19() model.compile(optimizer='sgd', loss='categorical_crossentropy', metrics=['accuracy']) print("Running initial batch (compiling tile program)") y = model.predict(x=x_train, batch_size=batch_size) # Now start the clock and run 10 batches print("Timing inference...") start = time.time() for i in range(10): y = model.predict(x=x_train, batch_size=batch_size) print("Ran in {} seconds".format(time.time() - start)) |
잘 돌기는 도는데 이게 지금 GPU 연산을 하는가? 라는 의문이 있었다.
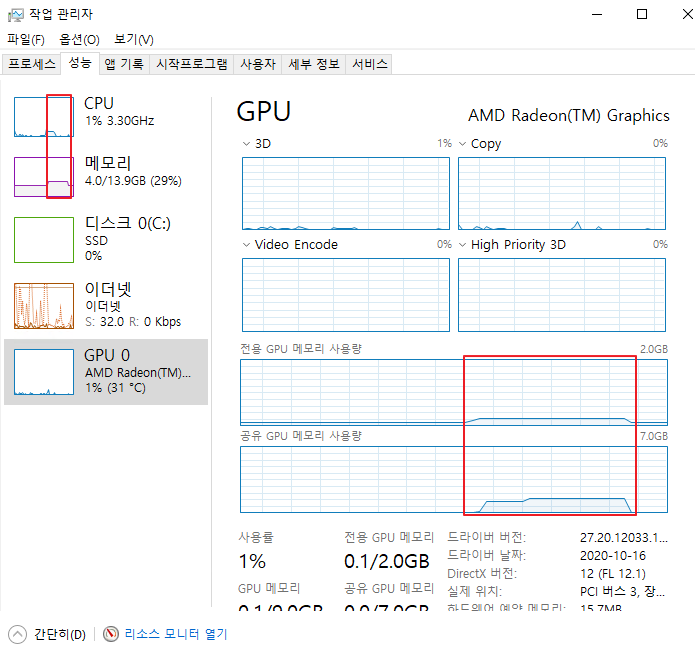
위와 같이 작업 관리자의 GPU 그래프가 너무나도 잠잠했기 때문에..
트레이닝을 시켰을때 GPU의 메모리 사용량이 늘은 것을 확인 했으나 GPU 코어 측정 부분이 가만히 있고 덩달아 시스템의 cpu / mem 사용량이 늘어 났다.
자세히 디버깅을 하면서 실행 해보니 AI 트레이닝 이전에 CPU/MEM 사용량이 먼저 증가 하였다 ‘ㅅ’a
구동 시나리오상 python도 같이 돌기 때문에 python 이 학습 및 테스트 데이터를 dataframe 에 넣을때 cpu 및 memory 사용량이 늘어나는것 같다.
윈도우 작업 관리자의 GPU 부분은 3D / Copy / Video Encoding, Decoding 등등만 보여주기 때문에 트레이닝시 GPU 로드 그래프 확인이 안되는것으로 추정 된다.
그래서 찾은 방법은 GPU-Z 를 설치해서 모니터링 하는 것이다.
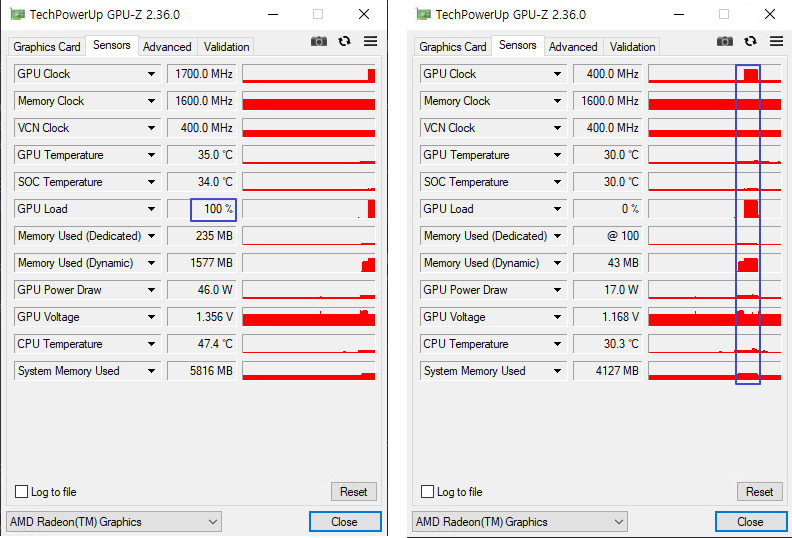
잘된다 🙂
다른 방법으로는 트레이닝 시간을 측정해 볼수 있겠다.
CPU연산을 했을때에는 5 columns, 110,281 rows 를 LSTM 연산을 했을때 약 35분 11초(2111초)가 소요 되는 트레이닝이 GPU 연산을 했을때 5분 46초(346초)로 단축이 되었다.
PS. PlaidML 은 intel 이 만들었고 keras backend 를 연결하여 intel, AMD gpu를 쓸수 있게 해주는 패키지 이다 ‘ㅅ’a
Nvidia 가 만든 CUDA를 이용하는 구글의 tensorflow 를 쉽게 쓰게 도와주는 keras…
이와 별개로 AMD가 구축하는 ROCm 이 있다 ‘ㅅ’a (이거는 나중에 스스로 공부할때 사용할 키워드를 주절주절 써놓은것…)