apache 재단에서 진행 되는 프로젝트 이다. python, java, R 등등 많은 언어를 지원 한다.
CSV (Comma-Separated Values)의 가로열 방식의 데이터 기록이 아닌 세로열 기록 방식으로 기존 가로열 방식에서 불가능한 영역을 처리가 가능하도록 한다.

보이는가 선조의 지혜가 -3-)b
이미지 출처: 훈민정음 나무위키
차이점을 그림으로 표현하자면 아래와 같다.
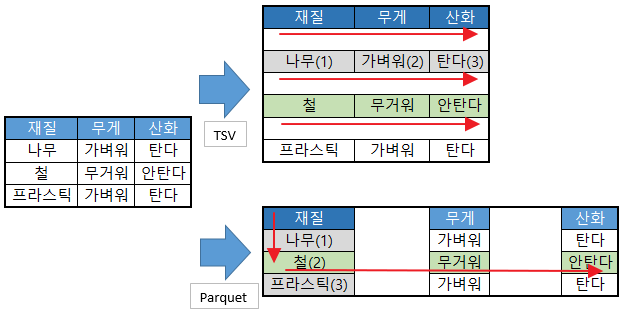
문서를 모두 읽는다 에서는 큰 차이가 발생하지 않지만 구조적으로 모든 행이 색인(index) 처리가 된 것처럼 파일을 읽을 수 있다.
sql 문으로 가정으로 “(SELECT * FROM 테이블 WHERE 재질 = ‘철’)” 을 찾게 될 경우 index 가 둘다 없다는 가정하에서
CSV 는 9개의 칸을 읽어야 하지만 (재질->무게->산화->나무->가벼워->탄다->철->무거워->안탄다->return)
parquet 의 경우 5개의 칸만 읽으면 된다. (재질->나무->철->무거워->안탄다->return)
PS. 물론 색인(index) 는 이런 구조가 아닌 hash 처리에 따른 협차법 으로 찾아서 빨리 찾을 수 있어 차이가 있다.
압축을 하더라도 컬럼별 압축이 되기 때문에 필요한 내용만 읽어서 압축해제 하여 데이터를 리턴 한다.
적당한 TSV (Tab-Separated Values)데이터를 준비 한다.
python 을 이용하여 TSV 파일을 읽고 python 의 pyarrow를 이용하여 parquet 파일을 생성 하고 읽는 테스트를 한다. (pyarrow, pandas 는 pip install pyarrow pandas 으로 설치할 수 있다.)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 |
#!/usr/bin/env python # -*- coding: utf-8 -*- import os import time import pandas as pd import pyarrow as pa import pyarrow.parquet as pq from pyarrow import csv def tsv2parquet(filename, skiphead, column_length, toformat): if toformat in ('none', 'snappy', 'gzip', 'lzo', 'brotil', 'lz4', 'zstd'): if skiphead == 0: skiphead = None table_columns = [str(i) for i in range(0, column_length)] r_opt = csv.ReadOptions(skip_rows=skiphead, column_names=table_columns, use_threads=False) p_opt = csv.ParseOptions(delimiter='\t') pyarrow_table = csv.read_csv(fname, read_options=r_opt, parse_options=p_opt) outname = os.path.splitext(fname)[0]+'.'+toformat+'.parquet' pq.write_table(pyarrow_table, outname, compression=toformat) else: print('didn\'t support format: '+ toformat) exit(1) return outname print('pyarrow version:', pa.__version__) # print pyarrow Version fname = "sample/shjang_Genome_20191011.txt" # Target file (TSV) sh = 4 # file header line. cc = 10 # column count out_format = 'gzip' # pyarrow 0.16 support: 'none', 'snappy', 'gzip', 'lz4', 'zstd' print('File size: ' + str(os.path.getsize(fname))) ts = time.time() outfile = tsv2parquet(fname, sh, cc, out_format) # make parquet file. print('make parquet(' + out_format + ') file: ' + str(round(time.time() - ts, 2)) + ' sec') ts = time.time() dataframe = pd.read_parquet(outfile, engine='pyarrow') print('parquet -> pandas -> dataframe: ' + str(round(time.time() - ts, 2)) + ' sec') ts = time.time() dataframe = pq.read_table(outfile).to_pandas() print('parquet -> pyarrow -> dataframe: ' + str(round(time.time() - ts, 2)) + ' sec') exit(0) |
TSV -> parquet 압축률(높을수록 좋음) 및 처리 시간(낮을수록 좋음)
| def | ext | MB | compress ratio | processing time python 2.7 | processing time python 3.6 |
|
|---|---|---|---|---|---|---|
| txt | .txt | 58.8 MB | ||||
| gzip | .txt.gz | 16.3 MB | 72% | 3.24 sec | ||
| pyarrow | write_table, compression='none' | .parquet | 40.1 MB | 32% | 0.74 sec | 0.93 sec |
| write_table, compression='snappy' | 24.8 MB | 58% | 1.31 sec | 0.95 sec | ||
| write_table, compression='lz4' | 24.7 MB | 58% | 0.79 sec | 0.94 sec | ||
| write_table, compression='zstd' | 19.3 MB | 67% | 1.00 sec | 0.98 sec | ||
| write_table, compression='gzip' | 18.8 MB | 68% | 5.07 sec | 1.18 sec | ||
읽기/쓰기 테스트 모두 AWS – EC2(m5.large-centos7) – gp2(100GB) 에서 진행 하였다.
parquet 을 생성한 이유는 파일을 읽을때 모든 컬럼인 index가 걸려있는것과 같이 빠르게 읽기 위함이니 읽기 테스트도 해본다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 |
#!/usr/bin/env python # -*- coding: utf-8 -*- import os import time import pandas as pd import pyarrow as pa import pyarrow.parquet as pq from pyarrow import csv def tsv2table2dataframe(filename, skiphead, column_length): table_columns = [str(i) for i in range(0, column_length)] r_opt = csv.ReadOptions(skip_rows=skiphead, column_names=table_columns, use_threads=False) p_opt = csv.ParseOptions(delimiter='\t') pyarrow_table = csv.read_csv(fname, read_options=r_opt, parse_options=p_opt) t1 = str(round(time.time() - ts, 2)) ts2 = time.time() pyarrow_df = pyarrow_table.to_pandas() t2 = str(round(time.time() - ts2, 2)) return pyarrow_df, t1, t2 print('pyarrow version:', pa.__version__) # print pyarrow Version fname = "sample/shjang_Genome_20191011.txt" # Target file (TSV) sh = 4 # file header line. cc = 10 # column count out_format = 'gzip' # pyarrow 0.16 support: 'none', 'snappy', 'gzip', 'lz4', 'zstd' print('File size: ' + str(os.path.getsize(fname))) ts = time.time() dataframe = pd.read_csv(fname, skiprows=sh, sep='\t', quotechar='"', header=None, index_col=None, error_bad_lines=False) print('text TSV file read with pandas to dataframe: ' + str(round(time.time() - ts, 2)) + ' sec') ts = time.time() dataframe = pd.read_csv(fname+'.gz', compression='gzip', skiprows=sh, sep='\t', quotechar='"', header=None, index_col=None, error_bad_lines=False) print('gzip TSV file read with pandas to dataframe: ' + str(round(time.time() - ts, 2)) + ' sec') ts = time.time() dataframe, t1, t2 = tsv2table2dataframe(fname, sh, cc) print('text TSV read(' + t1 + ' sec) with pyarrow to dataframe(' + t2 + ' sec): ' + str(round(time.time() - ts, 2)) + ' sec') ts = time.time() dataframe, t1, t2 = tsv2table2dataframe(fname+'.gz', sh, cc) print('gzip TSV read(' + t1 + ' sec) with pyarrow to dataframe(' + t2 + ' sec): ' + str(round(time.time() - ts, 2)) + ' sec') exit(0) |
TSV, parquet 파일 읽기 테스트 (pandas, pyarrow)
| def | ext | MB | processing time python 2.7 | processing time python 3.6 |
|
|---|---|---|---|---|---|
| pandas | read_csv | .txt | 58.8 MB | 1.39 sec | 1.56 sec |
| read_csv, compression='gzip' | .txt.gz | 16.3 MB | 1.68 sec | 2.06 sec | |
| read_parquet | .parquet (none) | 40.1 MB | 0.72 sec | 0.93 sec | |
| .parquet (snappy) | 24.8 MB | 1.03 sec | 0.95 sec | ||
| .parquet (lz4) | 24.7 MB | 0.73 sec | 0.94 sec | ||
| .parquet (zstd) | 19.3 MB | 0.76 sec | 0.95 sec | ||
| .parquet (gzip) | 18.8 MB | 0.96 sec | 1.18 sec | ||
| pyarrow | read_csv, to_pandas | .txt | 58.8 MB | 1.01 sec | 1.30 sec |
| .txt.gz | 16.3 MB | 1.41 sec | 1.37 sec | ||
| read_table, to_pandas | .parquet (none) | 40.1 MB | 0.69 sec | 0.90 sec | |
| .parquet (snappy) | 24.8 MB | 0.99 sec | 0.89 sec | ||
| .parquet (lz4) | 24.7 MB | 0.69 sec | 0.92 sec | ||
| .parquet (zstd) | 19.3 MB | 0.75 sec | 0.95 sec | ||
| .parquet (gzip) | 18.8 MB | 0.95 sec | 1.22sec |
이 문서 처음에 언급 했다 시피 대용량 파일을 처리 하기 위함. 즉 “빅데이터”(HIVE, Presto, Spark, AWS-athena)환경을 위한 포멧이다.
모두 테스트 해보면 좋겠지만 아직 실력이 부족해서 AWS athena 만 테스트를 진행 한다.
구조적으로 S3 버킷에 parquet 파일을 넣어 두고 athena 에서 테이블을(S3 디렉토리 연결) 생성 하여 SQL 문으로 검색을 하는데 사용 한다.
TSV, parquet 파일 읽기 테스트 (AWS – athena)
| ROW FORMAT SERDE | ext | Searched MB | processing time (select target 2) | processing time (select target 50) |
|
|---|---|---|---|---|---|
| athena | org.apache.hadoop.hive. serde2.lazy. LazySimpleSerDe | .txt | 58.8 MB | 1.17 ~ 3.35 sec | 1.86 ~ 2.68 sec |
| .txt.gz | 16.3 MB | 1.37 ~ 1.49 sec | 1.44 ~ 2.69 sec | ||
| org.apache.hadoop.hive. ql.io.parquet.serde. ParquetHiveSerDe | .txt.parquet | 10.48 MB | 1.11 ~ 1.49 sec | 1.00 ~ 1.38 sec | |
| .snappy.parquet | 4.71 MB | 0.90 ~ 2.36 sec | 0.90 ~ 1.00 sec | ||
| 지원 불가 | .lz4.parquet | 지원 불가 | |||
| .zstd.parquet | |||||
| org.apache.hadoop.hive. ql.io.parquet.serde. ParquetHiveSerDe | .gzip.parquet | 2.76 MB | 0.89 ~ 1.17 sec | 0.90 ~ 1.85 sec | |
읽는 속도가 향상되었고 스캔 크기가 적게 나온다. (parquet 의 강점을 보여주는 테스트-스캔비용의 절감이 가능.)
athena 테이블 생성에 사용된 DDL 쿼리문 (TSV, parquet)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
CREATE EXTERNAL TABLE IF NOT EXISTS [데이터베이스명].[테이블명] ( `rsid` string, `chr` string, `pos` int, `gt` string ) ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe' STORED AS INPUTFORMAT 'org.apache.hadoop.mapred.TextInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat' LOCATION 's3://[S3-URL]/[TSV폴더]'; CREATE EXTERNAL TABLE IF NOT EXISTS [데이터베이스명].[테이블명] ( `rsid` string, `chr` string, `pos` int, `gt` string ) ROW FORMAT SERDE 'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe' WITH SERDEPROPERTIES ('serialization.format' = '1', 'parquet.column.index.access'='true') LOCATION 's3://[S3-URL]/[parquet폴더]' TBLPROPERTIES ('has_encrypted_data'='true'); |
PS. 이건 저도 어려 웠어요…..